Investir dans l'humain ?
Mon, Jul 9, 2012Qu’est-ce qu’on va faire si on investit dans nos collaborateurs, et qu’ils s’en vont ?
…
Qu’est-ce qu’on va faire si on n’investit pas, et qu’ils restent ?…
Qu’est-ce qu’on va faire si on investit dans nos collaborateurs, et qu’ils s’en vont ?
…
Qu’est-ce qu’on va faire si on n’investit pas, et qu’ils restent ?…
 Jenkins
est certainement le serveur d’Intégration
Continue le
plus utilisé dans le monde. Si vous vous intéressez de près ou de loin à
l’open-source et que vous aimeriez contribuer à un projet de ce type,
lisez la suite.
Jenkins
est certainement le serveur d’Intégration
Continue le
plus utilisé dans le monde. Si vous vous intéressez de près ou de loin à
l’open-source et que vous aimeriez contribuer à un projet de ce type,
lisez la suite.
L’année dernière, en août, nous avons attaqué la traduction en français du Jenkins Definitive Guide, écrit en bonne partie par John Ferguson Smart. Le travail a avancé doucement, mais a avancé tout de même. A ce jour, sur la quinzaine de chapitres, trois sont traduits et relus, et presque tout le reste est en cours.
Ce n’est pas grave. Il y a plusieurs chapitres où il faut simplement relire, et donc parler français est suffisant. Si éventuellement, vous ne comprenez pas certaines parties traduites, et qu’il faut relire l’original, vous pouvez toujours soulever la question sur la liste de diffusion du projet où on parle français.
si vous voulez vous former à Git, c’est l’occasion. On se fera un plaisir de répondre à vos questions sur la liste de diffusion, même si elles sont exclusivement liées à Git, et pas (encore) à la traduction :-).
Mais si vous ne le sentez pas ou n’avez pas le temps, ce n’est pas grave. Vous devez simplement savoir éditer un fichier XML. Il y en a un pour chaque chapitre.
Si vous êtes intéressé, mais que vous avez des questions, surtout n’hésitez pas à les poser.
On vous attend ! :-)
I’m currently writing this article offline, since I’m in a place where even phones don’t work fine. Imagine the following situation:
So, what you would like to do is quite simple: work offline with git (it’s one of its best forces, right?), then push a mail somewhere with your commits. To do that, you have many possibilities:
So what’s left? git bundle. Let’s have a look at the documentation:
git-bundle - Move objects and refs by archive
Ahem, well, not very explicit if you ask me. Let’s look at the description:
Some workflows require that one or more branches of development on one machine be replicated on another machine, but the two machines cannot be directly connected…. This command provides support for git fetch and git pull to operate by packaging objects and references in an archive at the originating machine, then importing those into another repository using git fetch and git pull after moving the archive by some means (e.g., by sneakernet). …
More interesting.
I’ll rephrase it: we’re going to create a special archive, containing only the commits I want, and finally send it as an attachment. People receiving this mail will be able to just pull from this archive, as from a normal repository! Sounds great, doesn’t it?
So, how to use it? Here’s my use case: I have to do some kind of code review. So I’m gonna create a new branch from the main one “develop”, I’ll call that new one reviewFeatX. Then, that‘s at least the content of this branch I’d like to be able to send.
For bundling to be efficient and interesting, it’s assumed that both
repositories have a common basis. That’s quite obvious anyway: if the
repository you’re working on is totally new, then you are likely to have
to send it in its entirety. Sending “some commits” only makes sense when
there’s in fact commits already present in both places. 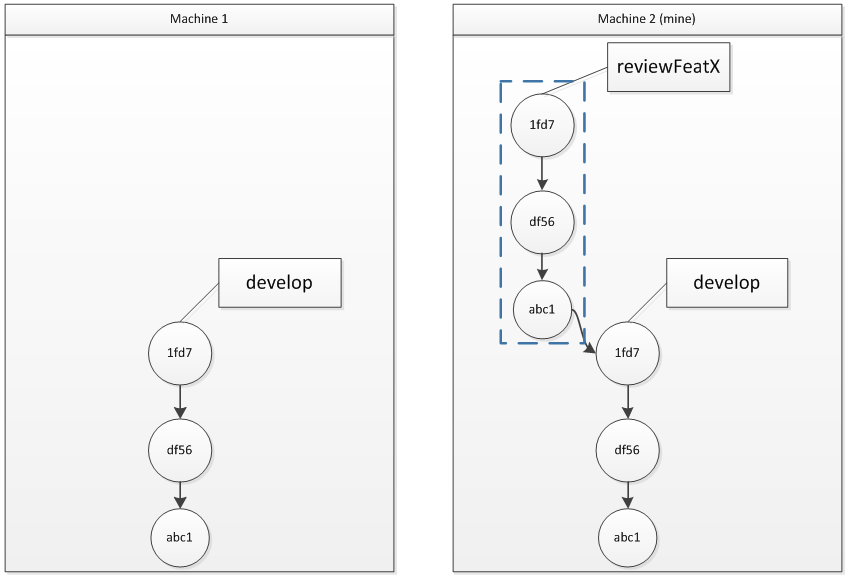
Thanks to git’s “everything-is-a-sha” policy + every commit has a parent, it’s quite easy for it to find the link between your work tree and another one.
Looking at the picture above, what we would like to do is quite obvious: send the blue part as an archive, and not a lot more if possible. Now, how do we do that?
$ git bundle create ../reviewFeatX.gitbundle develop..reviewFeatX
Notice the “develop..reviewFeatX”: this part will be passed through the git rev-list command, which will in fact return all the hashes (sha) corresponding to the blue part above in the diagram. Now you have a reviewFeatX.gitbundle file that you can send by email, dropbox or whatever you want.
On the other end of the pipe, someone is hopefully going to want to retrieve commits from the file. Here’s how to do that:
$ git bundle verify ../reviewFeatX.gitbundle
The bundle contains 1 ref
8c7feeb8d13233a466459cffc487ca08334af838 refs/heads/reviewFeatX
The bundle requires these 1 ref
6807f3ac794d72a410ac23fa8e2dc5c0bbd6c422 some log
../reviewFeatX.gitbundle is okay
$ git ls-remote ../reviewFeatX.gitbundle
1fd7 refs/heads/reviewFeatX
$ git fetch ../reviewFeatX.gitbundle reviewFeatX:reviewFeatX
From ../reviewFeatX.gitbundle
* [new branch] reviewFeatX -> reviewFeatX
$ git branch
* develop
master
reviewFeatX
$ git checkout reviewFeatX
Switched to branch 'reviewFeatX'
$ git log --oneline develop..reviewFeatX
1fd7 log3
df56 log2
abc1 log1
That’s it! You’ve now imported the commits from the bundle you received by mail.
As said in the introduction, you see there’s many ways to exchange commits. I hope you’ll have found this one interesting and that it will be useful to you.
Note: I wrote this post some months ago, and just made it public since the problem making it impossible to use was fixed some weeks ago. In the meantime, you should also be aware that Hudson has recently been renamed to Jenkins, and its new house is now http://jenkins-ci.org/
Sometimes, we encounter erratic issues accessing our subversion repositories. Even apart from the server upgrade information that just dont reach the interested people, but only managers who didn’t forward (since there’re obviously not the ones that use the dev server…), we also have random problems like everyone.
When SVN becomes unreachable, every one starts receiving mails about it from Hudson… For example, last week-end I received 6000+ emails about that. So, I wrote this small script to update all our jobs to not run during both the night and the week-end.
But sure, this won’t solve everything. For example, if the server goes down during a working-day, and you’re not in front of your computer for some reason. When coming back to your box, you might discover the big amount of mails from Hudson, or even from the devs if you’re in charge of operating the CI server.
So I’ve been looking for a way to just automatically disable Hudson builds when a problem is detected.
For some days now, I’ve been playing with the Hudson script console since I discovered how greatly powerful it can be.
My starting point was the hudson command used to prepare a shutdown. How to do it through the groovy console? I gave it here in one tweet: hudson.model.Hudson.instance.doQuietDown(). Once I found this, I just had to find a way to interact with the SVN inside the groovy/hudson console system and build around it a small groovy script.
After some struggle about how to programmatically use SVNKit (Subversion pure Java API), and then how to use an anonymous class with Groovy, I was done.
Here’s the resulting script:
import hudson.model.*
import org.tmatesoft.svn.core.*
import org.tmatesoft.svn.core.wc.*
String[] repoToCheck = ['svn://svn/scle', 'svn://svn:3691/pgih']
class MyHandler implements ISVNDirEntryHandler
{
def void handleDirEntry(SVNDirEntry dirEntry)
{
// nothing
}
}
org.tmatesoft.svn.core.internal.io.svn.SVNRepositoryFactoryImpl.setup();
Map<String, Throwable> problematicRepos = new LinkedHashMap<String, Throwable>();
for(String repo:repoToCheck)
{
SVNURL url = SVNURL.parseURIDecoded(repo);
SVNClientManager clientManager = SVNClientManager.newInstance();
SVNLogClient c = clientManager.getLogClient();
try
{
// Special groovy anonymous class construct
def handler = new MyHandler()
c.doList(url, SVNRevision.UNDEFINED, SVNRevision.HEAD, false, false, handler);
}
catch (Exception e)
{
problematicRepos.put(repo, e);
}
}
if(!problematicRepos.isEmpty())
{
for(Map.Entry<String, Throwable> entry:problematicRepos.entrySet())
{
println("Problem accessing \""+entry.getKey()+"\"");
String s = entry.getValue();
println(s)
}
println("Disabling hudson build")
hudson.model.Hudson.instance.doQuietDown()
return 1
}
else
{
println("No problems with repos");
}
Install the Groovy Plugin for Hudson. This way, you’ll be able to add job directly written in Groovy. Then create a job that will run every minute! ("* * * * *") and put the script above inside an “Execute system Groovy script”.
Then, configure the notification you like. It’s probably a good idea to target admin email when this jobs fails. That’s what I did.
Important note: there used to be a difference of behaviour with classloading between “groovy script console” and “groovy system script” in a job. This made the script above unable to work. The good news if that it was fixed with Hudson 1.352 and HUDSON-6068. So the bad news is that you can’t use this technique if you’re using an older version (time to upgrade? ;-)).
Sure the script isn’t perfect, here’s a few thought of what’s currently missing:
DAVRepository.setup() first.Hope this helps!
J’ai lu le livre Apache Maven, édité chez Pearson. Pour un premier livre en français sur Maven, on peut dire que l’expérience est globalement très réussie.
Disons-le tout de suite, je ne suis pas néophyte sur Maven. J’ai été utilisateur de maven 1 un tout petit peu (preuve ici :-)), avant de me plonger dans maven 2 depuis maintenant plusieurs années. Bon, ça c’est fait. J’espère que vous comprendrez que là, je veux pas me la péter hein. Je veux juste dire que nombre de concepts du livre m’étaient déjà connus. Et que, donc, mon analyse ne sera forcément pas celle d’un nouvel arrivant sur Maven.
J’avoue que j’ai trouvé la lecture très agréable. C’est volontaire de la part des auteurs, et c’est réussi. Ils ont réussi à apporter beaucoup de concepts dans un style facile à lire. Ils ne sont pas tombés dans le piège de la documentation de référence, parfois un peu dure à lire, voire carrément chiante, qu’on n’ouvrirait que pour y faire un grep sur ce qu’on cherche (et ce n’est à mon sens pas le but pour un livre papier).
Le livre se lit un peu comme un roman : un petit projet débute, et rencontre les problèmes classiques du packaging qui devient une usine à gaz, et que seul celui qui l’a développé (et encore) peut lancer. Au fil de l’eau, on explique donc comment fonctionne maven (et pourquoi il a été créé), comment packager simplement, etc. Ensuite, on se rend compte que l’écriture et le lancement de tests est fastidieuse, alors on explique comment ajouter des tests, et ainsi de suite en décrivant la mise en œuvre de choses de plus en plus complexes.
La première partie introduit maven, d’où il arrive, qui l’a créé et pourquoi. Exemple : un projet, quel qu’il soit (et dans quelque langage que ce soit), rencontre presque toujours les trois besoins suivants lors de sa construction : préparer la construction (initialisation), compilation, puis assemblage.
Tout y est, “convention-over-configuration”, la notion de dépendance, la transitivité, les scopes, les classifiers, etc… Et tout passe comme une lettre à la poste. Vraiment, je le redis : l’exploit de Nicolas et Arnaud réside dans la capacité à nous permettre de lire le livre sans avoir l’impression de lire une documentation technique.
Comme je le disais sur twitter, je pense que ce livre est un outil formidable sur lequel s’appuyer pour préparer des sensibilisations à Maven dans vos boîtes. Mais surtout, CITEZ VOS SOURCES !!! :-)
Dans la première partie, on la jouait petit. En tant qu’utilisateur expérimenté de maven, ça m’a surtout donné envie de voir comment on pourrait déployer Selenium et FitNesse en IC chez nous.
Là, on commence à ouvrir les vannes. Le projet est devenu complexe : comment gérer les dépendances proprement avec un repo manager, centraliser les informations dans un pom parent, utiliser Maven dans l’IDE.., et on arrive enfin à “mais diantre, comment on release un projet avec Maven ? On pourrait pas gérer automatiquement ces actions répétitives, rébarbatives qu’on se tape à chaque livraison, et sur lesquelles on se trompe une fois sur deux ?”.
On lâche les chevaux : écriture de plugin maison, comment le tester, intégrer de l’assurance qualité (analyse de code, couverture de code), la génération des rapports et enfin on parle de Sonar, la rolls de l’analyse qualité d’un projet.
Une fois la partie “technique” terminée, Arnaud et Nicolas se livrent même à l’exercice périlleux de prédiction : Maven 3 et consorts (Encore bon pour le moment : Maven 3 à attendre plutôt pour fin 2010, d’après le livre imprimé en novembre 2009. On en est à l’alpha-7 à ce jour.).
Il en faut, sinon, vous allez penser que je ne suis pas objectif :-).
Dans la description de ce petit projet devenu gros, j’ai retrouvé une très grande partie des choses que nous avons faites chez nous. Je pense que certains choix n’ont pas toujours été faits immédiatement, et la lecture d’un tel livre nous aurait économisé pas mal de temps et de recherches (le release-plugin marche très bien, une fois qu’il marche. Mais il peut être difficile d’initialiser les premières releases, où il y a toujours un truc qui plante au milieu).
Petit bonus en prime : le style adopté, et la partie à la fin du livre vous donnent l’impression de connaître tout le monde, de faire un peu partie de la famille :). Maintenant on connait l’âge de tous les développeurs francophones de Maven, même celui de Vincent qui a tenté un chiffrement en héxa :-).
Globalement, donc, je recommande chaudement ce livre à toute personne qui utilise maven et qui souhaite maîtriser l’outil. Le livre offre un accès facile à toutes les facettes du projet, des plus simples au plus avancées, sans omettre le côté humain qui est si important dans les projets opensource.
Il est possible par programmation de savoir d’où vient une classe : un jar ? un répertoire ? autre ?
Use case classique : vous pensez (et devez) ne plus avoir les commons-logging nulle part dans votre classpath, parce que vous êtes (intelligemment :-)) passés à SLF4J. Malgré cela, il semble que cette fichue classe soit toujours trouvée, mais vous n’arrivez pas à savoir dans quel jar (ou quel répertoire si vous travaillez directement avec les .class). Résultat, ça vous fout un bazar monstre dans la configuration de vos logs. Certains continuent à apparaitre alors que vous avez demandé à ce qu’ils ne soient pas affichés…
Le code est un peu sioux, alors je le mets ici au cas où ça vous servirait :
System.out.println(MaClasse.class.getProtectionDomain().getCodeSource().getLocation());
MAJ du 15/03/2010
Suite à l’incompréhension ci-dessous, voici quelques exemples pour illustrer ce que fait ce code :
Le code :
System.out.println(org.springframework.mail.MailSender.class.getProtectionDomain().getCodeSource().getLocation());
System.out.println(MyJunitTest.class.getProtectionDomain().getCodeSource().getLocation());
Affiche sous Windows :
file:/C:/m2repository/org/springframework/spring-context-support/2.5.6/spring-context-support-2.5.6.jar
file:/C:/tests/myproject-core/target/test-classes/
J’espère que l’utilité est un peu plus claire à présent.
Souhaitons que cette nouvelle année soit le début d’un retour aux manettes de ceux qui font à la place de ceux qui comptent. Mais j’avoue que j’y crois très peu :-).
Par le plus grand hasard, pendant la lecture d’un billet de Pascal sur les performances de firefox au fil des âges, je viens de m’apercevoir que je ne profitais en fait pas de TraceMonkey, le compilateur JIT intégré à Firefox depuis la 3.5 !
C’est vrai que je n’avais pas fait très attention, mais que je n’avais pas non plus remarqué d’amélioration notable sur mon navigateur favori. En fait, c’était à cause du fait que j’avais, comme tout bon développeur qui se respecte :-), installé firebug depuis déjà un bon moment.
Sur le blog de Pascal, la phrase suivante m’a donc fait tilter :
Un petit rappel si vous utilisez Firebug, votre moteur de compilation JIT de javascript est désactivé et vous aurez donc des perfs équivalentes à celles de Firefox 3.0, même si vous êtes en 3.5. La version 1.5beta7 de Firebug sortie hier devrait résoudre ce bug.
Aussitôt dit, aussitôt fait. J’ai installé la version 1.5X.0b8 de firebug et j’ai tout de suite vu effectivement une différence. Gmail, Google Reader, Hudson, tout s’affiche plus vite.
Comme j’avais fait le test SunSpider avant la mise à jour, en gros, je peux vous dire que je suis passé de 3500 à 1500 !
Bref, installez-vite cette mise à jour !
Je viens d’éclater de rire en voyant une publicité passer dans Gmail :

Le plus extraordinaire, c’est que le site en question semble pourtant se vouloir très sérieux :-).
Nous gérons en ce moment un petit problème d’intégration avec des WebServices d’une entreprise qui ne s’attend qu’à du iso-8859-1. XML a pourtant été conçu pour gérer plus simplement les problèmes de jeux de caractères et d’encodage utilisé, mais ce qui a été fait ne respecte tout simplement pas la spécification.
En effet, notre code envoie une requête SOAP dans un tube HTTP annonçant de l’UTF-8. Comme ça ne marchait pas, nous avons carrément ajouté l’attribut encoding au prologue XML et retesté avec Soapui, mais ça n’a rien donné.
Alors, comme il faut que quelqu’un corrige son code, j’ai vérifié la spécification^[1]^, voici ce qui est indiqué :
Bref, attendre de l’iso-8859-1 lorsque rien n’est indiqué est au minimum une bizarrerie, et au pire une erreur par rapport à ce que dit la spécification.
[1] Non-Normative