Mon, Jan 30, 2017
I was working recently on diagnosing unexpected tests failures that were only happening on our brand new Jenkins environment, and weren’t happening on the previous one.
To provide some context, we now run a majority of things in one shot Docker containers, and that helped reveal an interested issue.
The offending code
We have a test to check our code behaviour if a file we need to backup is readable or not.
It was roughly like the following:
// given
final File demo = File.createTempFile("demo", "");
FileOutputStream fos = new FileOutputStream(demo);
fos.write("saaluuuut nounou".getBytes());
fos.close();
// when
demo.setReadable(false);
// then (try to back it up, it should fail)
byte[] read = new byte[10];
new FileInputStream(demo).read(read);
System.out.println("Can I happily read that file? " + new String(read));
And weirdly enough, this test was failing.
By that I mean, there was no failure for the code above…
The reason
We were running those tests on a shiny new infrastructure, and using wrong Docker images using root user as the default.
For instance, if you use a base image like openjdk or basically any base image, you will hit this issue.
The thing is, when you are root, a bunch of things is not true anymore…
For instance, permissions…
If you don’t read Java, here’s a shell port of the Java code above:
$ echo hello > demo
$ chmod a-r demo
$ cat demo
cat: demo: Permission denied
But then replace the cat above by sudo cat:
I for one was slightly surprised root does not honor permissions at all.
Had I been given a quiz about this, I would probably have thought that being root would still prevent you from reading it (but being root would allow you to call again chmod at will to set what you need), but that’s how it is.
|
Note
|
Most of the Docker base images run the root user by default.
This is often for good reason: you are likely to use openjdk:8 for instance and need to install additional things.
But you must go the extra mile and switch to a normal user, using the USER instruction (either after having created one, or using a present one like nobody or something that suits your needs).
|
But running as root in a Docker container is OK right?
There has been articles out there explaining better than me why it’s not. Reducing attack surface, etc.
In my opinion, I hope this article shows this is clearly not the case, even for things like Continuous Integration/testing where one may think this is a special situation, hence acceptable exception.
Some people might argue that this is not the same situation anymore with the advent of the user namespace.
I will answer that though this is definitely a huge improvement, this does not change anything to the statement above.
Indeed, you will still be root in the container, and your code will NOT fail as it should for that kind of case (another example if need be: you would be allowed to use ports < 1024, when you should not).
And in the case of CI, you take the risk to miss corner cases because your CI environment will not be as close as possible to the production one.
And for pretty obvious reasons, well you want your tests to be run in something close to the production…
Conclusion
I think we can say it is a very common and accepted practice that running a server using the root user is a bad idea.
It is the same thing in Docker, for many reasons, and hopefully the examples given above will confirm it.
At least it was a lesson for me, and I’ll be very cautious about it from now on.
So, if you care about your tests, and their ability to monitor and reveal issues and regressions,
do NOT run your CI with the root user.
Sat, Dec 31, 2016
Working on validating the new Java 8 baseline of Jenkins, I needed some Windows environment to analyze some tests failure only happening there.
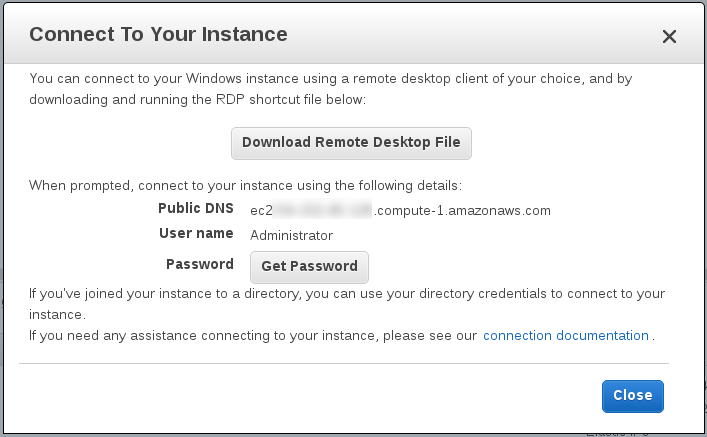
So, I went ahead to create an instance in Amazon Web Services to connect it to a Jenkins test instance.
It is actually pretty simple, but I thought I would explain it quickly here because it might help some people (like me next time) to save some minutes.
Launching your instance
It is out of scope here as it has nothing specific to our current use case. Just create an instance.
I am using the Microsoft Windows Server 2016 Base - ami-45e3ec52 for that article.
|
Caution
|
The only important thing is to make sure to keep the selected .pem file handy.
It will be necessary to retrieve the Administrator password once the instance is created.
|
Your instance is now running.
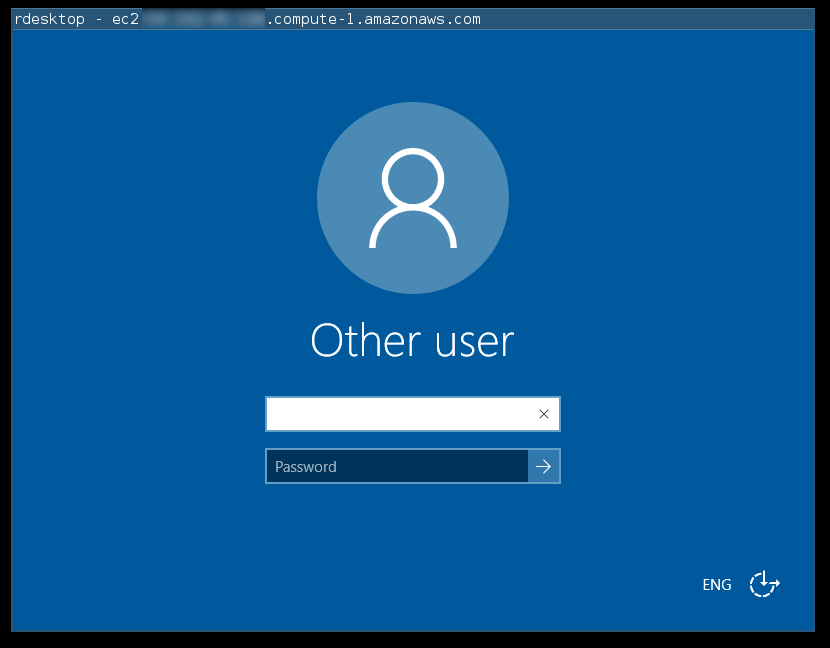
Connect to it
$ rdesktop ec2-54-152-45-128.compute-1.amazonaws.com
Autoselected keyboard map fr
Connection established using SSL.
WARNING: Remote desktop does not support colour depth 24; falling back to 16
This should quite slowly finally show the following screen:
-
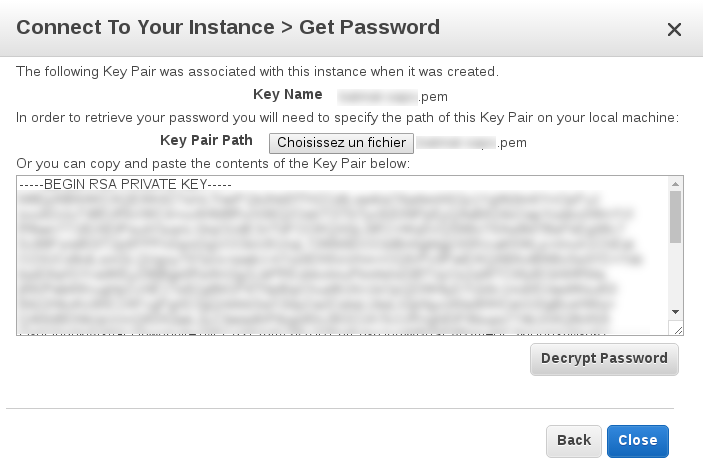
On the AWS Connect To Your Instance dialog open previously, click on the Get Password button.
-
Select the .pem file discussed above.
-
and click Decrypt Password.
You should now see the plain-text value of the password to connect to the instance.
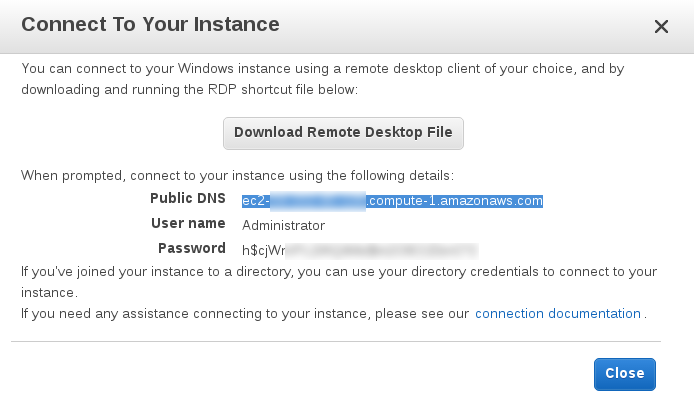
|
Note
|
I don’t know if this is specific to my environment, but if you’re lucky enough like me, copy-paste will not work.
So I had to manually copy paste the value…
Cumbersome with that password length.
|
Mon, Oct 17, 2016
Having had recently to refresh my memories and play with some new things about GC logging, I thought that ought to be a good opportunity to dig a bit on it, especially on log rotation.
Reminder: Always enable GC logging in production
If you run a production server, and you don’t have GC logs enabled, DO IT NOW.
Really, it could save your ass.
It is unnoticeable in terms of performance impact, and is invaluable if you need to diagnose some performance issue. It was a bit of a mess with HotSpot many years ago, since log rotation was not available. But now it’s been added for quite a long time, there is no excuse anymore.
OK, but I don’t know how to do that.
Then great, read below, this is the point of this article.
GC Logging: WAT?
The Garbage Collector is that thing that is going to go after you, and try to find unreferenced objects to clean up your work.
That cleanup can be done using a lot of different strategies.
It’s even pluggable in the JVM. So many are in use in the field.
They are called Serial, Parallel, Concurrent-Mark-Sweep aka CMS, Garbage First aka G1, and so on.
Explaining each one of those strategies is way out the scope of that article.
There is already a bunch of articles about them out there, and each one can easily require a whole article.
Still, knowing what the GC has been doing on a particular setup is essential for issue analysis and decision making.
The GC logs are non-standard outputs, depending on each strategy implementation, telling for example what was the previous available memory, what was freed, how much, and so on.
GC Log File Rotation
Now that you know you must always enable GC logging, the obvious way to do it is to use the options to output those logs into files.
The historical way to do that was simply to use -Xloggc:gc.log. Fortunately, for a few years now, since:
There is now a standard way to do it with HotSpot
.
TL;DR
Here is the full set of options I recommend to set up GC logs and its rotation:
java -Xloggc:gc.log \
-XX:+UseGCLogFileRotation
-XX:+PrintGCDateStamps \
-XX:GCLogFileSize=10m \
-XX:NumberOfGCLogFiles=10 \
-jar yourapplication.jar
|
Note
|
I verified those switches using a 1.8.0_102-b14 and a 1.7.0_79-b15 JRE (though Java 7 has been EOLed for 18+ months already).
|
- -XX:GCLogFileSize=10m
-
As always, it will depend on your environment, but this value should be safe for an average setup. For example, on an actual Jenkins production server with Parallel GC I just had a look on, known to be overloaded and probably suffering from a memory leak, the file was ~23 MB and spanned over 4 days.
So, 10 MB should let you have a file for something between a few hours a few days, which is what you need.
What you want to avoid is to have a value too high, that a memory issue will quickly span over multiple files, or even rotate to the point you start overwriting valuable recent data.
- -XX:NumberOfGCLogFiles=10
-
Again, here you are free to keep more, but if you read above, you will have understood that, unless you wish to keep data for later analysis for weeks or months of running, 10 or so should be enough in general.
- -XX:+PrintGCDateStamps
-
Though technically not needed, I prefer using that option to help humans analyze and correlate timestamps with events. It prefixes typical lines with a human readable timestamp (ISO-8601):
Example using Parallel GC, the default GC for servers setup
OpenJDK 64-Bit Server VM (25.102-b14) for linux-amd64 JRE (1.8.0_102-b14), built on Aug 25 2016 15:02:59 by "mockbuild" with gcc 6.1.1 20160621 (Red Hat 6.1.1-3)
Memory: 4k page, physical 16041916k(4476624k free), swap 8060924k(8060924k free)
CommandLine flags: -XX:GCLogFileSize=2097152 -XX:InitialHeapSize=256670656 -XX:MaxHeapSize=4106730496 -XX:NumberOfGCLogFiles=10 -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseGCLogFileRotation -XX:+UseParallelGC
0,066: [GC (Allocation Failure) 63488K->360K(241664K), 0,0016249 secs]
0,076: [GC (Allocation Failure) 63848K->392K(305152K), 0,0014354 secs]
Without it, the timestamp will only be a differential between the specified date at the beginning of the file and a gc event.
Same example, but with -XX:+PrintGCDateStamps
2016-10-17T07:27:25.360+0200: 9,407: [GC (Allocation Failure) 1336596K->276K(1504768K), 0,0015237 secs
Example using Java 7 and the Garbage First GC (aka G1)
2016-10-17 07:39:33 GC log file created gc.log.4
Java HotSpot(TM) 64-Bit Server VM (24.79-b02) for linux-amd64 JRE (1.7.0_79-b15), built on Apr 10 2015 11:34:48 by "java_re" with gcc 4.3.0 20080428 (Red Hat 4.3.0-8)
Memory: 4k page, physical 16041916k(189872k free), swap 8060924k(8060800k free)
CommandLine flags: -XX:ConcGCThreads=2 -XX:G1HeapRegionSize=1048576 -XX:GCLogFileSize=8192 -XX:InitialHeapSize=256670656 -XX:MaxHeapSize=4106730496 -XX:NumberOfGCLogFiles=10 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseCompressedOops -XX:+UseG1GC -XX:+UseGCLogFileRotation
2016-10-17T07:39:33.985+0200: 37,868: [GC pause (young)-- 3917M->3917M(3918M), 0,0053580 secs]
2016-10-17T07:39:33.991+0200: 37,873: [Full GC 3917M->3718M(3918M), 2,6648930 secs]
2016-10-17T07:39:36.656+0200: 40,539: [GC concurrent-mark-abort]
2016-10-17T07:39:36.691+0200: 40,574: [GC pause (young)-- 3913M->3823M(3918M), 0,0076050 secs]
2016-10-17T07:39:36.712+0200: 40,595: [GC pause (young) (initial-mark)-- 3915M->3915M(3918M), 0,0104690 secs]
2016-10-17T07:39:36.722+0200: 40,605: [GC concurrent-root-region-scan-start]
2016-10-17T07:39:36.722+0200: 40,605: [GC concurrent-root-region-scan-end, 0,0000090 secs]
2016-10-17T07:39:36.722+0200: 40,605: [GC concurrent-mark-start]
To sum up: don’t do it. Unless you perfectly know what you do.
Fine-Tuning things up-front is like asking a virtuoso pianist to play with handcuffs.
— Kirk Pepperdine (from memories)
I have been very lucky to follow the famous "Java Performance Tuning" training with Kirk some years ago.
He explained that nowadays the JVM has really become an impressive piece of engineering.
Especially, it now contains many auto-adaptive algorithms.
Fixing values like a pool size, the initial memory
and so on is likely to do more harm than good.
Unless it comes from actual testing, that is. Like GC logs analysis.
As always, you have to know what you’re doing and not blindly apply recipes, surprising isn’t it? :-)
References
-
GCEasy is a great online GC logs analyzer. I’m not affiliated with them, but really I’ve been impressed by what they do. Having used many tools like GCMV (each time a journey to find out ho to download and install it from IBM Website) in the past (what a mess to install each time), I’ve been dizzy with happiness finding such a cool online tool.
-
Sadly, I’m not referencing the (apparently) official HotSpot page about all that for now, since it contains at least TWO typos and it’s just wrong currently…
Sun, May 15, 2016
I have always been a tooling fan. Early in my career, now more than 10 years ago, I realized how much I love writing things making my life easier.
Open Source
I have also always liked to be part of opensource communities. Sharing knowledge and helping others, learning a lot in the process. Participating in things like Hibernate documentation translation, Hibernate forum, Apache Maven mailing lists, MOJO @ CodeHaus (now MojoHaus) Continuum, Archiva, M2E, Sonar[Qube], Hudson, and… Jenkins.
After switching from Apache Continuum, I started using Jenkins around 2009 when it was named a bit differently. My first message on the users mailing list seems to date back to early 2010.
My first code contribution to Jenkins seems to date back to 2011, where I had to git bisect a weird issue we were probably only very few to have, as we were using IBM AIX at that time.
Full Time Jenkins!
All those years, I have been spending a fair amount of time on that project close to my heart. So, having the opportunity to work full-time in "a professional opensource company" on all-things-Jenkins is obviously something strongly motivating to me.
I am thrilled to say I will be joining CloudBees next August.
I am very proud to soon start working with so many great individuals, bringing my small contribution to smoothifying the software delivery process in our industry.
Follow me on @bmathus to get more updates if you are interested :-).
Wed, Aug 26, 2015
DISCLAIMER: I’m not a system expert. What follows is more an aggregation of things I’ve tried and informations gathered on the Internet. I also wrote it to serve as a placeholder for myself. I make sure to provide many links so that you can make your own opinion. Please don’t hesitate to give feedback if you disagree with some statements below.
For some months now, we’ve started deploying more and more Docker services internally to progressively gather experiences.
After encountering a few issues, mainly related to storage, I’ve started to read a lot about the Docker Storage drivers.
Docker default behaviour (with DeviceMapper): Wrong
As much as I love Docker, some may find a pity that the default behaviour is NOT to be used in production (on a non-ubuntu host)!
Indeed, by default, here’s what Docker will choose as a storage driver:
BUT, the thing is: though AUFS is apparently great for Docker (was used by DotCloud for their PaaS, before it became public), it’s not in the standard kernel. And is unlikely to be in the future.
For this reason, distributions like RedHat (which is upstream-first) chose to support devicemapper instead, in the so-called thin provisioning mode, aka thinp.
But by default, if AUFS is not found in the current kernel, Docker will fallback to the ubiquitous devicemapper driver. And for the default again, it will create loopback files. This is great for newcomers bootstrapping, but horrible from a least surprise principle perspective: since this mode MUST NOT be used in production.
So, I can use still Devicemapper, if I make sure to use thinp?
Longer one: many Docker knowledgeable people have publicly stated that you should prefer other ones. Many have even recommended that you default to using Overlay :
@codinghorror more specifically we’ve never seen devmapper work reliably… Overlayfs support is pretty good now. Also zfs & btrfs.
Even Daniel J Walsh aka rhdan, working for RedHat has stated :
Red Hat kernel engineers have been working hard on Overlayfs, (Perhaps others on the outside, but I am not familiar). We hope to turn it on for docker in rhel7.2 BUT […]
Device Mapper is a complex subsystem
I can’t help thinking that this sentence may tell us more about the subject than his author was thinking. Complexity often being the reason software can not survive years? Might be.
Conclusion: if in doubt, use overlay
I’ve started converting the Docker hosts I work with from devicemapper to overlay. My first impressions are good and everything seems to be working as expected .
From all I’ve read, my current wager is that overlay will soon become the default driver. It has the pros of devmapper (no need to create a FS for one) apparently without much of its cons.
Only some specific use cases will still make people choose other drivers like btrfs or zfs. But as these require to create and size real FS to be used, they are unlikely to be used as widely.
Fri, Jul 24, 2015
I was not actually planning to write that, more something about Docker.*
these days. But that’s how it is.
For many reasons lately, I’ve been thinking about my career and what I
wanted to do. By the way, I absolutely, positively recommend you listen
to that episode (35 minutes, seriously it’s worth it).
The part that made me think about that article is when Jeff talked about
making things you do visible. Providing context. Understanding people’s
needs.
Architect Failure
Though I retrospectively think I should maybe have pushed sometimes some
more evolved/involved solutions, I’m not actually talking about a
technical failure.
No, I’m talking about human/social one.
To simplify a bit, the management decided to reorganize the development
with dev teams on one side, and a separate architecture team.
Because I had earned technical respect from (at least some of) my
coworkers, it went not so badly initially. Some teams were asking for
reviews, or even for solutions for issues/requirements they had.
But for some people, developers and maybe even more managers, we were
intruders. Not welcome.
What I did
Mainly, I think I stayed in my office way too much, and took that
position for granted. Kind of the Ivory Tower issue (well, without the
tone I hope. I’ve tried hard to not be condescending especially because
of how much I despised self-said Architects who didn’t code).
I thought the requests were going to flow naturally. How wrong, and
dumb, I was.
Don’t get me wrong. I was not hiding and playing video-games on my
computer :-). I was actually working for some teams. But even those
teams eventually didn’t even ask us for help, and worked us around.
What I should have done
I should have hanged out more with the teams (which is somehow
ironic I didn’t when you know me). Go see them, ask them if they
were needing help. Get involved with them. Simply be more empathetic.
Let them know what we did, why, for whom, constantly. Make that publicly
available.
I should also have refused to work on some subjects supposed to be
useful in 1 or 2 years, without any actual need. How many hours I lost
on useless PoCs, studies, that will never get used.
Wrap up
That made me realize something. Something that may be obvious to more
experienced people: the fact that the current management structure, the
current organization will NOT stay as-is forever. And that you should
always strive to break barriers, reach out the people who do the actual
work and help them, work with them.
This way, people will know you’re basically useful wherever you are, and
whatever position you hold. And that might also transitively prove your
team is useful.
If you don’t, then you’re dead. At the next shakeup, you’ll be wiped
out. And you will have deserved it.
Thu, Oct 2, 2014
Dans l’article qui suit, je vais vous montrer comment j’ai récemment eu l’occasion
d’utiliser Docker pour un cas concret.
La particularité ici est que cela était un cas utile à un travail de développement :
cela n’avait pas pour but de faire tourner une application,
simplement d’accéder à un environnement (via Docker, donc), de récupérer des informations,
puis de jeter.
Pour ce cas, j’estime avoir gagné au bas mot plusieurs dizaines de minutes.
Le contexte
Alors que je travaillais sur une
pull request pour le projet maven-scm,
j’ai eu besoin pour les tests d’intégration d’une vieille version de Subversion
(oui, j’utilise Git sinon :-)).
Plus précisément, j’avais besoin de pouvoir faire un checkout d’un dépôt SVN avec
les métadonnées au format SVN 1.6.
Or, ma machine est à jour, et la version que j’ai en local est une récente 1.8.8…
Que faire ?
- Rétrograder la version de ma machine ? Bof, pas trop envie de risquer de péter mon existant.
- Une VM ? Où ? En local ? Pfiou, ça va être long… En IaaS ? Bof.
- …
Mais dis-donc !
Docker à la rescousse
Au final, cette manipulation m’a pris maximum 5 minutes. Le plus long a été de trouver sur
Google la version du paquet debian correspond à SVN 1.6
la bonne version de Debian (pour aller au plus simple, puisqu’on pourrait aussi prendre une version plus
récente et tenter d’installer une version spécifique de SVN).
Sur https://packages.debian.org/search?keywords=subversion, donc :
Paquet subversion
squeeze (oldstable) (vcs): Système de contrôle de version avancé
1.6.12dfsg-7: amd64 armel i386 ia64 kfreebsd-amd64 kfreebsd-i386 mips mipsel powerpc s390 sparc
wheezy (stable) (vcs): Système de contrôle de version avancé
1.6.17dfsg-4+deb7u6: amd64 armel armhf i386 ia64 kfreebsd-amd64 kfreebsd-i386 mips mipsel powerpc s390 s390x sparc
wheezy-backports (vcs): système de gestion de version évolué
1.8.10-1~bpo70+1: amd64 armel armhf i386 ia64 kfreebsd-amd64 kfreebsd-i386 mipsel powerpc s390 s390x
jessie (testing) (vcs): système de gestion de version évolué
1.8.10-2: amd64 arm64 armel armhf i386 kfreebsd-amd64 kfreebsd-i386 mips mipsel powerpc ppc64el s390x
sid (unstable) (vcs): système de gestion de version évolué
1.8.10-2: alpha amd64 arm64 armel armhf hppa hurd-i386 i386 kfreebsd-amd64 kfreebsd-i386 m68k mips mipsel powerpc ppc64 ppc64el s390x x32
1.8.8-2: sparc
1.7.13-3 [debports]: sparc64
1.6.17dfsg-3 [debports]: sh4
OK, on va donc partir sur une version stable.
$ sudo docker run --rm -it debian:stable /bin/bash
root@d2645d786f6e:/# apt-get update
[snip]
root@d2645d786f6e:/# apt-get install subversion zip
[snip]
root@d2645d786f6e:/# svn --version
svn, version 1.6.17 (r1128011)
compiled Mar 12 2014, 02:44:28
[snip]
root@d2645d786f6e:/# svn co -N http://svn.apache.org/repos/asf/maven/pom/trunk/asf/
A asf/pom.xml
A asf/site-pom.xml
U asf
Checked out revision 1629441]
root@d2645d786f6e:/# zip -rq asf.zip asf
Ensuite, depuis le host, dans un autre onglet de votre émulateur de terminal favori :
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dbd6d39cbdb1 debian:stable "/bin/bash" 25 minutes ago Up 25 minutes sick_archimedes
$ sudo docker cp sick_archimedes:/asf.zip .
$ unzip -t asf.zip
Archive: asf.zip
testing: asf/ OK
testing: asf/.svn/ OK
testing: asf/.svn/dir-prop-base OK
testing: asf/.svn/props/ OK
testing: asf/.svn/entries OK
testing: asf/.svn/all-wcprops OK
testing: asf/.svn/tmp/ OK
testing: asf/.svn/tmp/props/ OK
testing: asf/.svn/tmp/prop-base/ OK
testing: asf/.svn/tmp/text-base/ OK
testing: asf/.svn/prop-base/ OK
testing: asf/.svn/prop-base/pom.xml.svn-base OK
testing: asf/.svn/prop-base/site-pom.xml.svn-base OK
testing: asf/.svn/text-base/ OK
testing: asf/.svn/text-base/pom.xml.svn-base OK
testing: asf/.svn/text-base/site-pom.xml.svn-base OK
testing: asf/pom.xml OK
testing: asf/site-pom.xml OK
No errors detected in compressed data of asf.zip.
Et voilà, en à peine quelques minutes, j’ai mon checkout, je jette mon conteneur, et je continue.
Je sais pas vous, mais moi c’est ce genre de petit exemple tout simple qui me place
du côté de ceux qui disent que Docker n’est pas une simple nouveauté, mais effectivement
une véritable révolution !
Mon, Oct 7, 2013
Michäel Pailloncy et
moi allons animer un atelier lors de
l’AgileTour Toulouse 2013, jeudi 10 octobre (cf. les détails de la
session). Oui, c’est dans 3
jours :-).
Quelques informations complémentaires si vous prévoyez de venir à cet
atelier :
- sachez qu’il nécessite absolument un ordinateur. Si vous n’en
avez pas, libre à vous de venir avec un ami qui en a un, mais ce
sera probablement moins intéressant pour vous.
- vous devrez aussi disposer d’un client Git fonctionnel (nous
clonerons un dépôt local fourni sur la clé USB car nous n’aurons pas
accès à Internet).
- la machine devra posséder un JDK en version 7 installé. Nous en
fournirons les binaires sur une clé USB, mais vous gagnerez beaucoup
de temps si vous n’avez pas à le faire en début de TP.
Cf. aussi le dépôt GitHub suivant et son
README
Si vous avez besoin de précisions, n’hésitez pas à me contacter via
Twitter ou dans les commentaires de ce
billet.
Merci de votre attention, faites passer le message :-).